



BIM 칼럼니스트 강태욱의 이슈 & 토크
이번 호에서는 생성형 AI 모델 학습과 같이 현재도 다양한 곳에서 필수로 사용되는 강화학습 딥러닝 기술의 기본 개념, 이론적 배경, 내부 작동 메커니즘을 확인한다.
■ 강태욱
건설환경 공학을 전공하였고 소프트웨어 공학을 융합하여 세상이 돌아가는 원리를 분석하거나 성찰하기를 좋아한다. 건설과 소프트웨어 공학의 조화로운 융합을 추구하고 있다. 팟캐스트 방송을 통해 이와 관련된 작은 메시지를 만들어 나가고 있다. 현재 한국건설기술연구원에서 BIM/GIS/FM/BEMS/역설계 등과 관련해 연구를 하고 있으며, 연구위원으로 근무하고 있다.
이메일 | laputa99999@gmail.com
페이스북 | www.facebook.com/laputa999
홈페이지 | https://dxbim.blogspot.com
팟캐스트 | http://www.facebook.com/groups/digestpodcast
강화학습은 바둑, 로봇 제어와 같은 제한된 환경에서 최대 효과를 얻는 응용분야에 많이 사용된다. 강화학습 코딩 전에 사전에 강화학습의 개념을 미리 이해하고 있어야 제대로 된 개발이 가능하다. 강화학습에 대해 설명한 인터넷의 많은 글은 핵심 개념에 대해 다루기보다는 실행 코드만 나열한 경우가 많아, 실행 메커니즘을 이해하기 어렵다. 메커니즘을 이해할 수 없으면 응용 기술을 개발하기 어렵다. 그래서 이번 호에서는 강화학습 메커니즘과 개념 발전의 역사를 먼저 살펴보고자 한다.
강화학습 개발 시 오픈AI(OpenAI)가 개발한 Gym(www.gymlibrary.dev/index.html)을 사용해 기본적인 강화학습 실행 방법을 확인한다. 참고로, 깃허브 등에 공유된 강화학습 예시는 대부분 게임이나 로보틱스 분야에 치중되어 있는 것을 확인할 수 있다. 여기서는 CartPole 예제로 기본적인 라이브러리 사용법을 확인하고, 게임 이외에 주식 트레이딩, 가상화폐, ESG 탄소 트레이딩, 에너지 활용 설비 운영과 같은 실용적인 문제를 풀기 위한 방법을 알아본다.
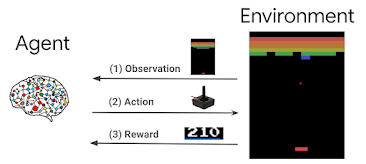
그림 1. 강화학습의 개념(출처 : Google)
강화학습의 동작 메커니즘
강화학습을 개발하기 전에 동작 메커니즘을 간략히 정리하고 지나가자.
강화학습 에이전트, 환경, 정책, 보상
강화학습의 목적은 주어진 환경(environment) 내에서 에이전트(agent)가 액션(action)을 취할 때, 보상 정책(policy)에 따라 관련된 변수 상태 s와 보상이 수정된다. 이를 반복하여 총 보상 r을 최대화하는 방식으로 모델을 학습한다. 정책은 보상 방식을 알고리즘화한 것이다. <그림 2>는 이를 보여준다. 이는 우리가 게임을 하며 학습하는 것과 매우 유사한 방식이다.
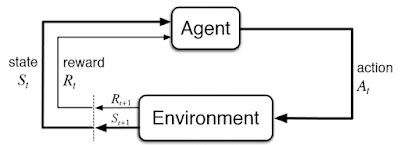
그림 2. 강화학습 에이전트, 환경, 액션, 보상 개념(출처 : towardsdatascience)
강화학습 설계자는 처음부터 시간에 따른 보상 개념을 고려했다. 모든 시간 경과에 따른 보상치를 동시에 계산하는 것은 무리가 있으므로, 이를 해결하기 위해 DQN(Deep Q-Network)과 같은 알고리즘이 개발되었다.
모든 강화학습 라이브러리는 이런 개념을 일반화한 클래스, 함수를 제공한다. 다음은 강화학습 라이브러리를 사용한 일반적인 개발 코드 패턴을 보여준다.
train_data, test_data = load_dataset() # 학습, 테스트용 데이터셋 로딩
class custom_env(gym): # 환경 정책 클래스 정의
def __init__(self, data):
# 환경 변수 초기화
def reset():
# 학습 초기 상태로 리셋
def step(action):
# 학습에 필요한 관찰 데이터 변수 획득
# 액션을 취하면, 그때 관찰 데이터, 보상값을 리턴함
env = custom_env(train_data) # 학습환경 생성. 관찰 데이터에 따른 보상을 계산함
model = AgentModel(env) # 에이전트 학습 모델 정의. 보상을 극대화하도록 설계
model.learn() # 보상이 극대화되도록 학습
model.save('trained_model') # 학습된 파일 저장
# 학습된 강화학습 모델 기반 시뮬레이션 및 성능 비교
env = custom_env(test_data) # 테스트환경 생성
observed_state = env.reset()
while not done:
action = model.predict(observed_state) # 테스트 관찰 데이터에 따른 극대화된 보상 액션
observed_state, reward, done, info = env.step(action)
# al1_reward = env.step(al1_action) # 다른 알고리즘에 의한 액션 보상값과 성능비교
# human_reward = env.step(human_action) # 인간의 액션 보상값과 성능비교
■ 상세한 기사 내용은 PDF로 제공됩니다.




